VR Headset
This work presents Interactive Conversational 3D Virtual Human (ICo3D), a method for generating an interactive, conversational, and photorealistic 3D human avatar. Based on multi-view captures of a subject, we create an animatable 3D face model and a dynamic 3D body model, both rendered by splatting Gaussian primitives. Once merged together, they represent a lifelike virtual human avatar suitable for real-time user interactions. We equip our avatar with an LLM for conversational ability. During conversation, the audio speech of the avatar is used as a driving signal to animate the face model, enabling precise synchronization. We describe improvements to our dynamic Gaussian models that enhance photorealism: SWinGS++ for body reconstruction and HeadGaS++ for face reconstruction, and provide as well a solution to merge the separate face and body models without artifacts. We also present a demo of the complete system, showcasing several use cases of real-time conversation with the 3D avatar. Our approach offers a fully integrated virtual avatar experience, supporting both oral and written form interactions in immersive environments. ICo3D is applicable to a wide range of fields, including gaming, virtual assistance, and personalized education, among others.
Method Overview. Users interact with the avatar through text or audio queries, which are processed by a LLM to generate textual responses that are synthesized into speech. The generated speech drives the animatable head model (HeadGaS++) and controls body motion via procedural animation (SWinGS++). Head and body 3D Gaussians are integrated and rendered jointly, producing free-viewpoint video synchronized with the spoken audio.
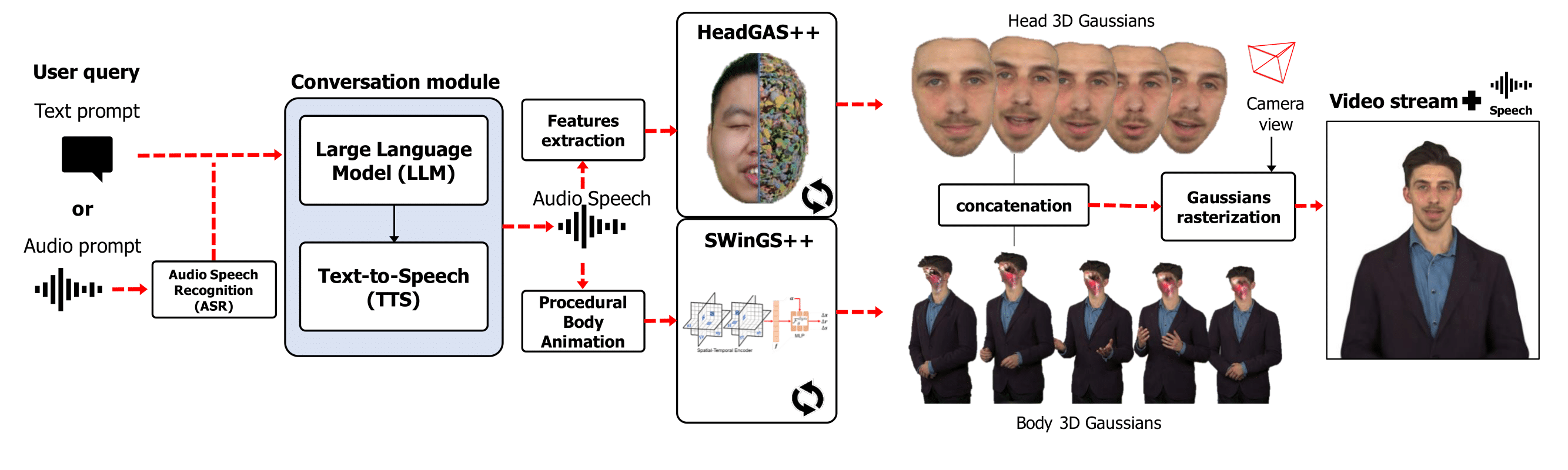
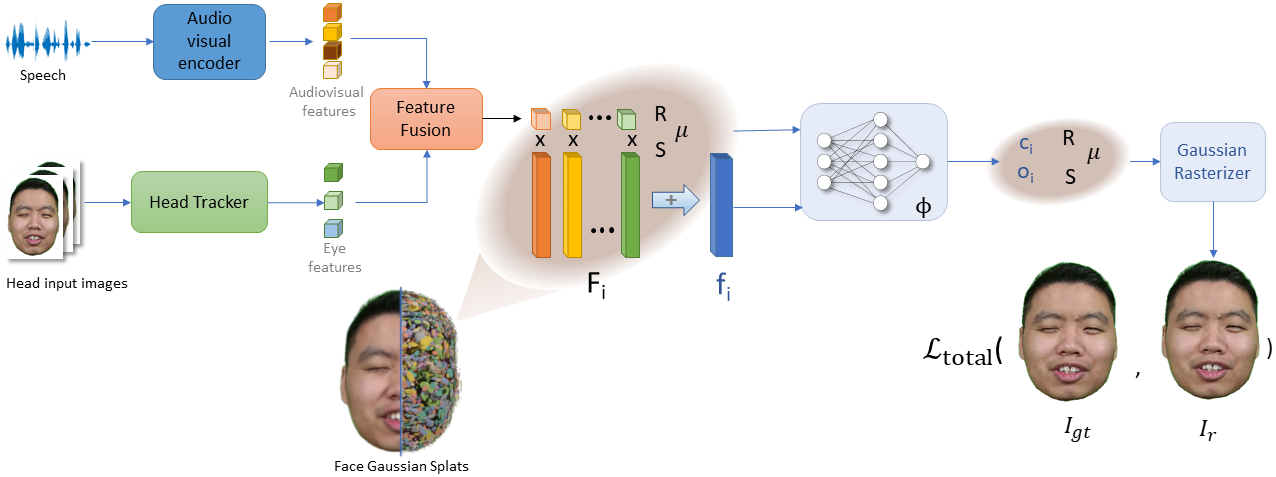
HeadGaS++ is an extension of our animatable head model HeadGaS, which uses features extracted from audio speech to drive the facial expressions.
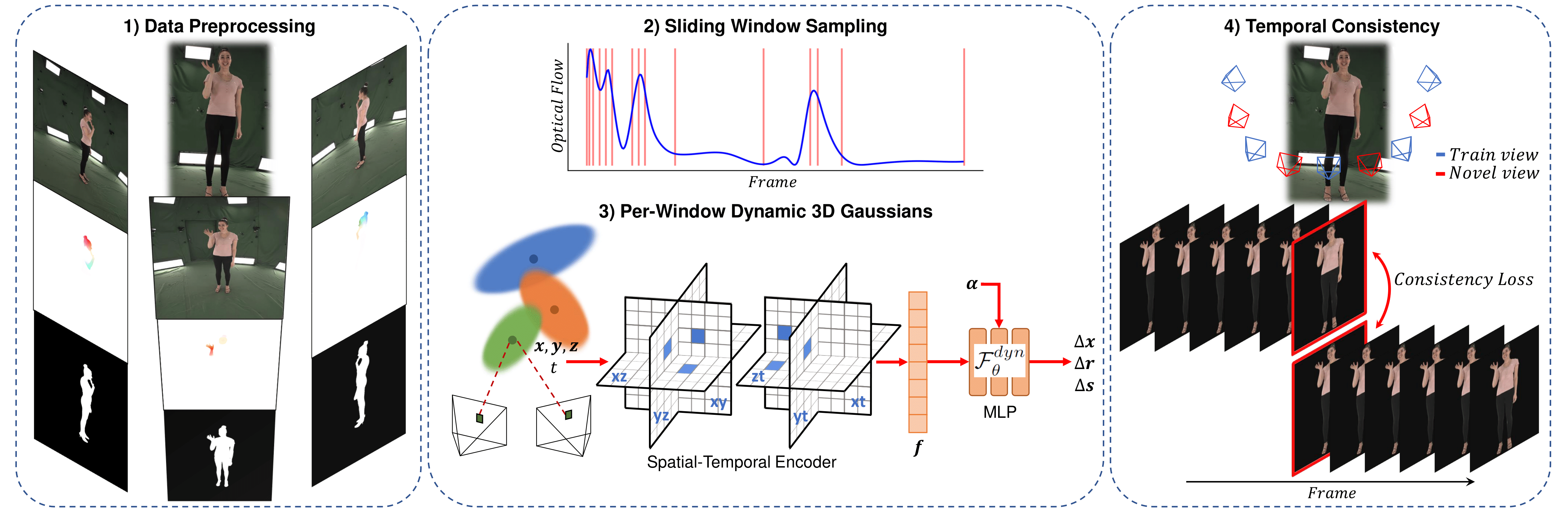
SWinGS++ is an extension of our 4DGS model SWinGS, which uses temporally-local MLPs on a sliding window basis. The method is extended using a spatial-temporal encoder to better reconstruct human motion.
@article{shaw2025ico3d,
title={ICo3D: An Interactive Conversational 3D Virtual Human},
author={Shaw, Richard and Jang, Youngkyoon and Papaioannou, Athanasios and Moreau, Arthur and Dhamo, Helisa and Zhang, Zhensong, and P{\'e}rez-Pellitero, Eduardo},
journal={arXiv preprint},
year={2025}
}